

投稿日
社内AIチャット「TIS AIChatLab」:RAG応答評価の仕組みとプロセス
もくじ
はじめに
TISは、生成AIを活用した自社データと連携する社内専用のChatGPT環境である「TIS AIChatLab」の開発・利用を進めています。これは、大規模言語モデル(LLM)を基盤とし、企業固有の情報を活用できるよう拡張したシステムです。本記事は「TIS AIChatLab」のプロジェクトメンバーへのインタビューを通して、TISにおけるLLMやRAGに関する取り組みを紐解くシリーズの第2回です。
今回は評価の仕組み、作業プロセス、指標などの評価部分にフォーカスしてお届けします。
インタビュアー
水谷:会員制メディアAIDBの運営者。LLMなど機械学習の知見を論文ベースで紹介している。
サマリ
- 社内専用のAIチャット「TIS AIChatLab」の開発では、RAGASを活用したAIの応答を定量的に評価している。これにより、パフォーマンスを客観的に測定し、継続的な改善を可能にしている。
- 評価プロセスには、評価データセットの作成、バッチ処理による評価、結果分析、改善策の立案が含まれる
- 主な課題として評価用クエリの作成や評価対象の絞り込みがあり、今後は本番データの分析や継続的な改善が計画されている
応答評価の仕組みについて
山口さん(以下、山口):RAG(Retrieval-Augmented Generation)は、与えられた質問に対する回答を生成する際に、社内文書データベースから関連情報を検索(Retrieval)し、その情報を基にして新しいテキストを合成(Generation)するプロセスです。検索性能を満たさない(データ品質が低い、検索性能が低い)場合、ユーザーの利便性に達せず、利用されない状態になります。
TISでは”システム品質”と”データ品質”を両立できる「RAG応答評価の構築 + 応答改善専門チーム」の体制をとっています。

ーRAG応答評価の仕組みについて教えていただけますか?
山口:応答評価の仕組みは図のように構築しています。Weights and Biases(以下WandB)を使用し、細かい内部ログを記録し、定量評価のためにLLMによる応答評価を行います。そして出力結果をレポートにまとめ、チームで改善のための分析を行っています。

首藤さん(以下、首藤):レポートの内容を少し詳しく説明しますと、AIの性能を評価する際の質問、それに対してAIが行った回答、そして我々が期待していた回答(グラウンドトゥルース)を記録しています。
また、回答の評価指標として、Answer Correctness(回答の正確性)とAnswer Similarity(回答の類似性)という2つの指標を使用しています。

ーグラウンドトゥルース(期待される回答)は人の手で作成するのですか?
首藤:はい、基本的に人手で作成しています。具体的な方法としては、例えば情報システムに関する質問であれば、そのシステムの運用者や開発者、責任者に「この質問に対する正しい回答は何でしょうか」と確認します。また、実際の問い合わせ履歴からFAQリストのようなものがあれば、そこから適切な回答を抽出することもあります。最終的に、どういう回答をしたいかを質問して調整するという形で作成しています。
応答評価のプロセスについて
ー評価の作業プロセス全体の流れを教えていただけますか?
山口:まず、評価のデータセットを作成します。これは、ユーザーから想定される質問と期待される回答のセットです。FAQデータが整備されている場合はそれをそのまま使えます。そうでない場合、例えば規約のようなまとまった文章であれば、それを基に1問1答の形式に起こします。作成にはLLMを用いたり、社内の業務有識者と協力して進めます。

このデータセットは、データドメインごとに100件から600件ほどの大量のデータになります。それらを使って、バッチ処理で一気に回答評価ができるようなスクリプトを用意しています。そのスクリプトに流し込んで、先ほどお話しした評価指標の結果を出力します。

その後、出力された結果を読み、回答できていないものや問題がある箇所を確認します。定量的な指標も参考にしながら、どこがうまくいっているか、うまくいっていないかを判別し、原因の分析と課題の仮説を立てて、レポートにまとめていきます。
ーLLMを使った評価とはどのようなものなのでしょうか?
首藤:評価には2つの指標を使用しています。LLMを使用しているのはAnswer Correctness(回答の正確性)の方法です。Answer Similarity(回答の類似性)の方はエンベディングモデルを使用しているため、LLMによるテキスト生成は使用していません。
Answer Correctnessの評価方法としては、期待する回答と実際にAIが回答した文章をLLMに入力し、両方の文章に含まれる事実の情報だけを抽出するよう指示します。具体的には、期待する回答にしかない事実、実際に生成された回答にしかない事実、どちらにも共通して存在している事実という3つの要素を評価するようLLMに指示しています。
ー評価用のプロンプトの作成には苦労されたのでしょうか?
首藤:RAGASという評価フレームワークを使用しており、基本的な評価用のテンプレートが提供されていたため、初期評価のハードルは高くありませんでした。
ただし、RAGASは元々英語のテキストを評価するために最適化されています。日本語のテキストを評価するためにどう調整するかという点で、若干の工夫が必要でした。RAGASから提供されている日本語用の設定もありましたが、実際にプロンプトに適用する際にどう変換するかというところで苦労しました。
ー2つの評価指標を採用した理由はなんでしょうか?
首藤:Answer CorrectnessとAnswer Similarityの2つを選んだ理由は、これらがend-to-endの指標だからです。
RAGASで紹介されている他の指標は、文脈やコンテキストの内容がどれだけ一致しているかなど、LLMの個々のコンポーネントに注目するものです。それらの指標は、モデルチューニングまで行うような、LLMを非常に細かくチューニングする場合には重要になってきます。
私たちは基本的にプロンプトチューニングとRAGに注力しており、モデル自体のチューニングにはそこまで注力しない方針でした。そのため、end-to-endの指標を見れば十分だろうと判断し、この2つの指標を選びました。
ー定量評価以外に計測・記録したものはありますか?
首藤:はい、応答速度も記録しています。評価を進める中で、LLMが回答に要する時間が課題になってきたので、応答速度が良くなっているか悪くなっているかを記録し、改善に活かしています。
また、内部処理の詳細も記録しています。アプリで回答を生成する際には、実際にはLangChainを使用しています。その中でどの部分に時間がかかっているのか、あるいは回答の内容がおかしいと感じた時に、どこで誤りが発生したのかを追跡するために、LangChainの処理内容を詳細にトレースしています。1
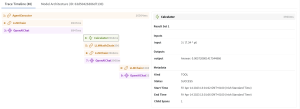
詳細分析では、例えば必要な情報を正しく取得できているか、取得できていない場合はなぜなのか(データベースに情報がないのか、検索クエリが適切でないのか)などを調査しています。
LLMが具体的にどうしてある回答を生成したのかという、より詳細な分析については、LLMアプリに詳しい別のチームメンバーに相談し、仮説を立てて検証するというプロセスも行っています。
ー評価対象となるデータセットは全体で何件くらいでしたか?また、エラーや改善が必要なケースはどのくらいの割合でしたか?
山口:初回の改善レポートでは全体で数百件のデータセットを評価しました。そのうち、良好な結果(Answer Correctnessが0.5以上)が得られたのは4割ほどでした。それ以外のケースについては、詳細な分析を行いました。例えば、正しい情報は見つかったものの、別のドキュメントから取得していたケースや、検索はヒットしたが誤った解釈をしていたケースなどがありました。そういった切り分けを行なっていき、それぞれの改善策を整理していきます。分析結果はレポートに詳細にまとめています。
ー1件1件詳しく原因を調べて、実装部分を改善していったということですね。
首藤:はい。特に初期の段階では、なぜそのような結果になったのかを理解するのが非常に難しかったです。アプリケーションの動作を把握することから始めて、細かく分析を行いました。この分析結果を基に、アプリケーションの改善点や評価の仕組み自体の不備なども特定し、対応策をまとめました。

ーそのような綿密な仕組みを作って、決めた通りに実行していくのが素晴らしいですね。
山口:そうですね。そうした反復的なプロセスで、一度評価したものも再評価していきました。定量的な指標を用いて前回評価との差分をチェックすることで、ステークホルダーにも説明がしやすくなりました。

応答評価の構築~ 応答改善達成までの道のり
ー評価の仕組みを構築し始めてから完了するまでの流れを時系列で教えていただけますか?
山口:はい、全体の流れをお話しします。
- 1月15日:プロジェクトのキックオフ
- 1月末:WandBの初期設定を開始。また、評価データセットの作成を開始
- 2月初旬:品質保証計画の立案を開始
- 2月中旬:バッチ評価スクリプトの作成を開始
- 2月21日:初回のバッチ評価を試行開始。この時点ではスクリプト処理時間などの課題も見つかる
- 3月初旬:特定のデータケースに対し、応答評価を開始。2回の評価サイクルを実施し、段階改善
- 3月19日:改善後の初回リリース
初回リリース後も、改善サイクルを継続しています。性能やスピードの改善を含めて、定期的に評価と改善を行っています。
浦上さん(以下、浦上):2024年4月中旬に2回目の改善リリースを行いました。初回リリースでは一部のデータのみを評価対象としていましたが、次第に評価範囲を広げていきました。つまり、インデックスに格納しているデータ全体を評価したわけではなく、いくつかの領域に分けて評価対象を絞り、段階的に評価と改善を行うアプローチをとっています。

浦上:社内ユーザーに対しては、評価対象となる全データ量を提示した上で、評価を実施した具体的な範囲を明示しました。その中で、高精度を達成した領域を特定し、報告しています。さらに、こうした高精度領域を段階的に拡大していくことを目標として、継続的な改善活動を展開しています。
評価用のデータセット作成の難しさ
ー評価範囲を広げた際、既存の改善で対応できましたか?それとも新たな課題が発生しましたか?
浦上:評価用のデータセット作成で、新たな課題がみえてきました。他部門と協力して評価を進める中で、当初は質問と回答の両方を他部門に作成してもらう予定でしたが、工数の関係で難しくなりました。
そこで、アプローチを変更し、評価対象のデータの基となっているドキュメントをもとに、LLMを使ってベースとなる質問と回答を生成しました。ただし、LLMで生成したものをそのまま使うのではなく、生成したものを他部門に見てもらい、「これは回答できている」とか「これはできていないね」という評価をしてもらいました。そして、その評価済みのデータを使って実際の評価を行いました。
ただその後、定性評価を中心に行った結果、回答自体はそれほど質が低くないことがわかりました。つまり、正しく回答できているものが多かったのですが、Answer CorrectnessやAnswer Similarityといった定量的なスコア自体は想定より低いという状況でした。
LLMで質問と回答のペアを作る際の工夫が足りなかったことや、他部門にレビューしてもらう際の観点の伝え方が不十分だったことなどが原因として考えられます。例えば、他部門の方々に「正解としてOKかどうか」というよりも、「回答として適切かどうか」という判断をしてもらってしまい、評価の際にスコアが上がりにくくなってしまいました。
これらの経験から、評価用のクエリとグラウンドトゥルースをより適切に作成することが課題であると認識しています。ただし、業務の都合上、完璧な評価データを作るのは難しいため、どのようにアプローチすべきか検討中です。
RAGの応答評価における重要なポイント
ーRAGの応答評価における重要なポイントとはなんでしょうか?
首藤:ひとつは、評価対象のデータセットを絞り込みです。
AIに回答させたい情報は非常に広範囲で様々な業務分野を含みます。社内情報で言うと、人事、総務、経理、情報システムなど。これら全てを評価しようとすると、何千件という単位の質問と回答のセットを作成し、全てを確認することになります。全件の評価をリリースのたびに行うのは現実的ではないため、対象のデータセットを絞り込むことが必要です。できるだけ少ないデータセットで全体の応答評価が測れるものをピックアップします。どのように対象を絞り込むか、工夫が必要です。
評価対象の絞り込みについては、質問の種類を分類し、各分類からサンプルを抽出する方法を採用しました。例えば、FAQデータがある場合、その分類を利用してサンプリングを行いました。
FAQの分類(例:「この分野に関する質問」「この種類に関する質問」など)があれば、そのグループから代表的な質問を1つ取り出して評価するというアプローチを取りました。それで全体をカバーしつつも、評価対象の絞り込みを行っています。
ーそのアプローチは今後の他のプロジェクトにも応用できそうですね。
首藤:そうですね。ただし、評価データセットの作り方には様々な要素があるので、一概に言いにくい部分もあります。データの種類や量、プロジェクトの目的などによって、最適なアプローチが変わってくる可能性があります。
一般的なアプローチとしては、質問文の類似度を基にグループ化し、各グループからサンプルを抽出する方法があります。例えば、自然言語処理技術を使って質問の類似度を計算し、類似度の高いグループからサンプルを1件採用するといった方法です。我々はそこまで厳密にはやっていないので次回以降に試したいことですね。
山口:このノウハウは文書化しにくい部分もあるので、実際に経験したエンジニアがいることが私たちの強みになると思います。
ー応答性能をどこまで細かく評価するか、評価基準を設けるかは難しい判断ですね。
浦上:そうですね。実は、具体的なスコアなど明確なリリース基準は設けていません。現状では、評価した結果の報告にとどまっています。基本的には、現行版と比較して性能が落ちていれば対応する、という形です。数値的な指標を伸ばすことより、ユーザーに価値提供できているかが重要です。
応答性能をどこまで上げるかという点とは少し異なりますが、世の中で出ているRAGの改善手法などを参考に、TIS AIChatLabに適用できそうなものを確認し、優先度を決めて適用していっています。応答評価プロセスが安定して回せるようになってから、UX改善も並行して行えるようになりました。
RAGの評価データセット作成プロセスの改善点
ープロセスの改善を行っている点についてお聞かせください。
浦上:プロセスの改善点という意味では、先ほども少し触れましたが、評価クエリの質の問題があります。グラウンドトゥルースの質が良くなかったケースもあったので、改善する必要があります。
また、4月のリリース時に情報システム部門と協力して評価を進めたと言及しましたが、他部門との情報のやり取りや連携方法についても改善の余地があります。LLMとは直接関係ないかもしれませんが、丁寧にコミュニケーションを取ることの重要性を再認識しました。これも改善点の一つですね。
ー未経験者がこのようなプロジェクトに取り組む際に注意すべき点や、次に同様のプロジェクトを行う人へのアドバイスなどはありますか?
首藤:最も重要なのは評価データセットの作り方だと思います。リリース前に性能評価をする場合、質問を想定し、期待する回答も想定して自分たちで作らなければなりません。
その際に注意すべき点として、各部門の専門家が期待する回答と、実際にAIに回答させたい内容にずれが生じることがあります。このずれを理解し、適切に修正することが重要です。例えばグラウンドトゥルースの作成時に、回答のフォーマットや形式についてルールを決めておくことが大切です。「回答はこういうフォーマットで、こういう形式でお願いします」というように、明確なガイドラインを設けることが有効です。
ー評価データセットの作成方法については、今後も継続的な課題になりそうですね。
浦上:このプロジェクトを通じて、評価の仕組み作りの難しさと重要性を改めて実感しました。今後も改善を続けていきます。
今後の展望
ー今後の展望を教えてください。
山口:現在、「TIS AIChatLab」の社内の利用数が格段に増えており、ユーザーが実際に多く使っているクエリや回答できていないクエリなどのデータが自然と集まってきています。これらのデータを自然言語処理で分類し、それに対応していくフローを構築しています。
集まったデータをどう活かしていくかというのが非常に重要だと思います。AI ChatLabチームでは、本番データの分析に取り組み始めています。社内業務の重要なタッチポイントを起点に、AI精度の向上や施策企画に活用し、ユーザーの利便性向上とコスト削減を両立していきます。
また「AIエージェントフロー」を採用したレポート作成などの社内の高度タスクへの適応にも着手していきます。
ー今回お伺いした内容は、世の中にはあまり公開されていない、組織レベルでのRAGプロジェクトの知見になりそうですね。
山口:社内AIチャット(RAG)の機能提供は実現できても、ユーザーの利便性に達するまでの応答範囲と精度を満たせていない企業は、実は多いのかなと思います。
検索性能を満たさない(データ品質が低い、検索性能が低い)と、ユーザーの利便性に達せず徐々に利用されなくなります。システム品質だけでは価値につながらず、データ品質も上げる必要があるのです。そこには必ず経験あるエンジニアが必要となります。
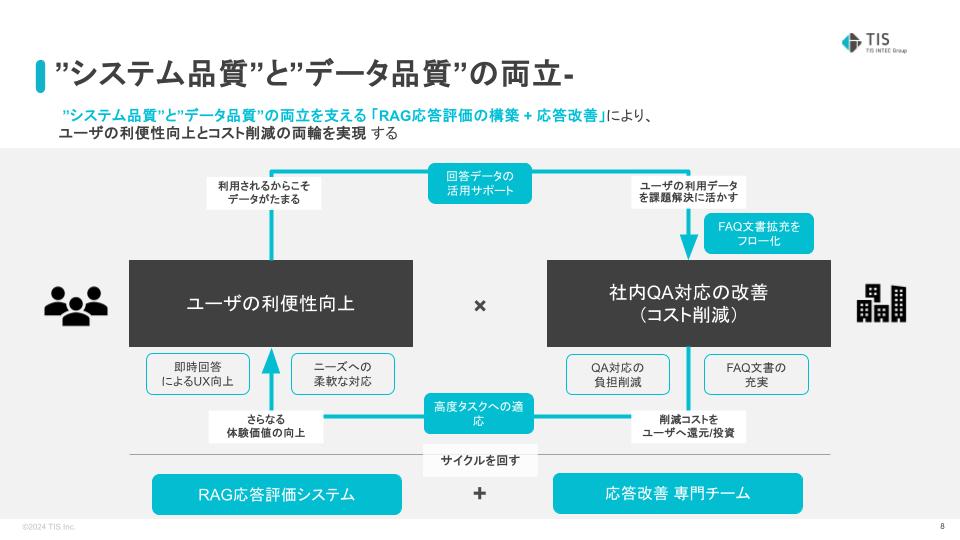
山口:システムは改修しない限り変更がないのに対し、インプットとなるデータは常に変化していきます。変化するデータに対し「汎化性能」を担保し続けていくためには、”システム品質”と”データ品質”を両立できる「RAG応答評価の構築 + 応答改善専門チーム」が必要です。
技術特性が多い領域で、かつ、データ内容には企業の業務特性と個別性が含まれるため、人による解釈を含む運用が必須です。
データと応答精度の保全という RAGOpsはSIerが価値を発揮する領域 だと考えています。お客様の業務変革の実現と提供価値の向上に向けて、私たちの強みを届けていきたいです。
まとめ
TISのAI ChatLabプロジェクトはLLMとRAGの実践的な応用に取り組んでいます。このプロジェクトから以下の知見が得られました。
- 評価システムの重要性:WandB、RAGASを活用し、AIの応答を定量的に評価。これにより、パフォーマンスの改善を客観的に測定し、継続的な改善を可能にしています。
- 評価プロセスの確立:評価データセットの作成、バッチ処理による評価、結果分析、改善策の立案という一連のプロセスを確立しました。このプロセスにより、システムの性能を効率的に向上させています。
- 継続的な改善の重要性:評価用クエリの作成や評価対象の絞り込みなどの課題に対して、LLMを活用したクエリ生成や、質問の分類によるサンプリング、本番データの分析や新たな改善手法の適用などの工夫を重ねて、継続的な改善に取り組んでいます。これは、AIシステムの長期的な有効性を維持するために不可欠なプロセスです。
AI技術の急速な進歩に伴い、このような実践的な取り組みの重要性はますます高まっていくと考えられます。
TISでは全社的に生成AIを活用していく方針があり、TIS AIChatLabで培ったノウハウをビジネスに繋げ、収益に貢献することを目指しています。
1. LangChainは、以下ライセンスに基づいて利用しています。↩︎
MIT License
Copyright (c) LangChain, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the “Software”), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.