

投稿日
AWS Fargateを使ったAmazon ECSでAkka Clusterを安定稼働させる ─方式編─
もくじ
- 想定読者
- 背景
- 環境構成
- アプリケーションの特性
- Akka Clusterを用いたアプリケーションを構成する
- 1. sbtでコンテナイメージをビルドできるようにする
- 2. ECRにコンテナイメージをpushする
- 3. Akka ManagementとAWS APIディスカバリーモジュールの導入
- 4. ヘルスチェックAPIの有効化
- 5. Split Brain Resolverの設定
- 6. アプリケーションの起動・停止シーケンスの調整
- Akka Clusterのアプリケーション向けにECSを設定する
- 1. コンテナヘルスチェック
- 2. コンテナ停止タイムアウト
- 3. ECSサービスのデプロイタイプ(バージョンアップ方法)
- Akka Clusterのアプリケーション向けにNLBを設定する
- ヘルスチェック
- さいごに
はじめまして。テクノロジー&エンジニアリングセンター Lernaチームの根来です。
本エントリではAmazon Elastic Container Service(以降、ECS)上でAkka Clusterを稼働させるために検討した方式を公開します。ECSの起動タイプはAWS Fargate(以降、Fargate)を想定します。以降、単にECSと表記された部分では起動タイプにFargateを使う前提であると解釈してください。
本エントリを読むと次のことがわかります。
- Akka Clusterを用いたアプリケーションをECS上にデプロイする方法
- そのアプリケーションをゼロダウンタイムでアップデートする方法
想定読者
- Akka Clusterをローカル環境などで起動したことはあるが、ECS環境では起動したことがない方
Akka Clusterが相互通信しながら処理することや、起動時にシードノードを指定する必要があることなど、Akka Clusterの基本的な仕様を理解していることを想定します - Dockerでコンテナを起動したことがある方コンテナイメージやコンテナといった基本的な概念を理解できていることを想定します
背景
私たちは高可用ソフトウェアスタック「Lerna」を開発しています。LernaではAmazon Elastic Compute Cloud (Amazon EC2)上にAkka Clusterを用いたアプリケーションをデプロイする方法を提供しています。しかし、EC2の運用にかかるコストを削減する目的で、ECS上にアプリケーションをデプロイしたいという声がありました。
Lernaはプラットフォームに依存せず、高い可用性を実現するシステムを構築できることを価値のひとつとしています。ECSをLernaのサポートプラットフォームに加えるため、私たちはAkka Clusterを用いたアプリケーションをECS上で稼働させられるのか検証することにしました。
私たちのこの活動を次の2回に分けて紹介します。本エントリはその1回目です。
- ECSでAkka Clusterを用いたアプリケーションを稼働させる方式(本エントリで紹介する内容)
- Akka Clusterを用いたアプリケーションを実際にECSへデプロイし検証した結果
運用コストを削減するという目的に沿うよう、できるだけAWS(Amazon Web Services)のマネージドサービスを用いて検証環境を構成します。
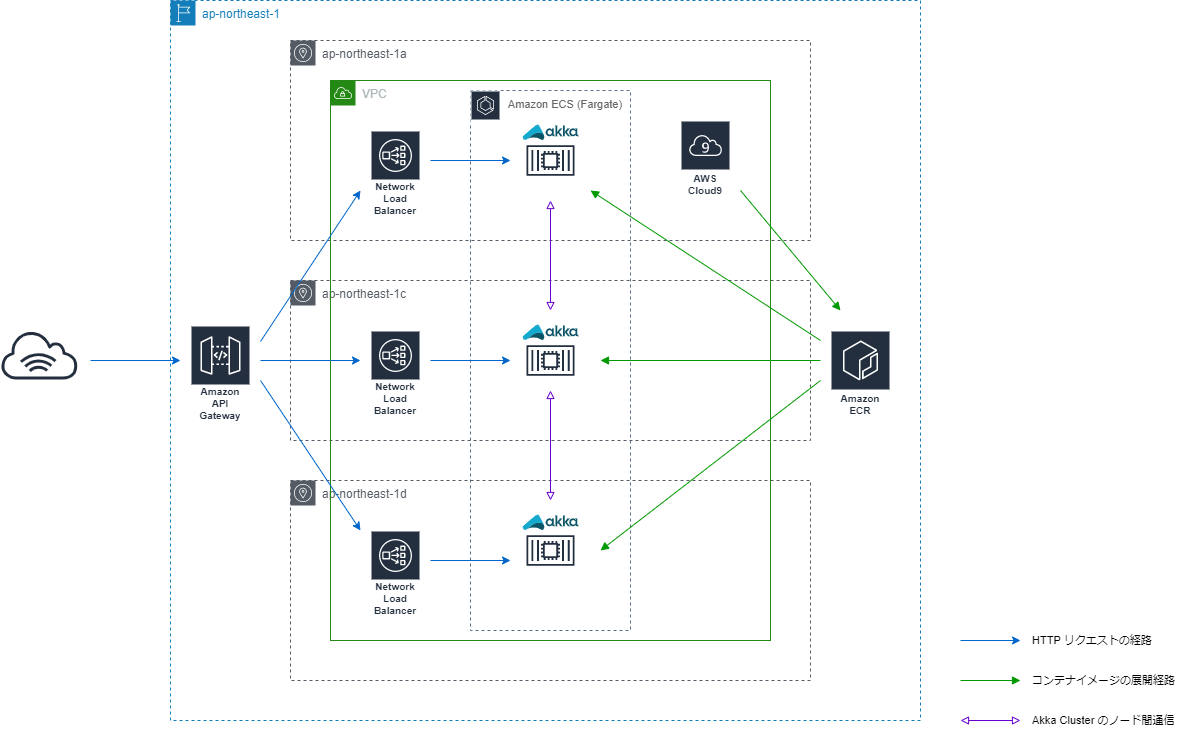
環境構成
本エントリで紹介する方法は、次のような環境でAkka Clusterのアプリケーションを稼働させることを目標とします。
- Akka ClusterのアプリケーションはECS上で起動し、起動タイプはFargateとする
- 東京リージョンの3つのAZ(アベイラビリティーゾーン)にコンテナを分散する
- インターネットからのHTTPリクエストはAmazon API Gatewayで受け、Network Load Balancer(以降、NLB)でバランシングする
- コンテナイメージのビルドとAmazon Elastic Container Registry(以降、ECR)への登録はAWS Cloud9(以降、Cloud9)から行う
アプリケーションの特性
本エントリで扱うアプリケーションには次のような特性があることを想定します。
- Akka Cluster Shardingを用いたステートフルなアプリケーションである
- Akka HTTPを用いてHTTP APIを提供するアプリケーションである
Akka Clusterを用いたアプリケーションを構成する
Akka Clusterを用いたアプリケーションを本エントリで想定しているECSの環境向けに構成するには、次のような作業が必要だと想定されます。
- sbtでコンテナイメージをビルドできるようにする
- ECRにコンテナイメージをpushする
- Akka ManagementとAWS APIディスカバリーモジュールの導入
- ヘルスチェックAPIの有効化
- Split Brain Resolverの設定
- アプリケーションの起動・停止シーケンスの調整
1. sbtでコンテナイメージをビルドできるようにする
sbt-native-packagerを使うとsbtでアプリケーションのコンテナイメージを作成できます。
project/plugins.sbt
addSbtPlugin("com.github.sbt" % "sbt-native-packager" % "1.9.4")enablePluginsとビルドするコンテナイメージの設定を行います。 本エントリのアプリケーションではアプリケーションで実装したAPIのリクエストを9001番ポートで受け、 Akka Clusterのノード間通信ではデフォルトの25520番ポートを使うと想定します。 実装するアプリケーションの構成に合わせて適宜ポート番号を読み替えてください。
build.sbt
lazy val root = (project in file("."))
.enablePlugins(JavaAppPackaging, DockerPlugin)
.settings(dockerPackageSettings)
// 以降略
// FIXME: アプリケーションの構成によって適宜変更してください
// 詳細: https://www.scala-sbt.org/sbt-native-packager/formats/docker.html
lazy val dockerPackageSettings = Seq(
mainClass in Compile := Some("com.example.Main"),
packageName in Docker := (name in ThisBuild).value,
dockerBaseImage := "adoptopenjdk:8-jdk-hotspot",
dockerExposedPorts := Seq(
9001, /* HTTP (service API) */
25520, /* TCP (Akka Cluster/Remote) */
),
)動作確認などのためローカル環境でコンテナを動かしてみたい場合は、次のコマンドを実行することでローカルのDockerにビルドされたコンテナイメージを登録できます。
❯ sbt docker:publishLocal2. ECRにコンテナイメージをpushする
sjednac/sbt-ecrを使うとsbtでECRにコンテナイメージをpushできます。sbt-native-packagerと組み合わせることで、コンテナイメージのビルドからpushまでの一連の作業をコマンドをひとつで実行できるようになります。
project/plugins.sbt
addSbtPlugin("com.mintbeans" % "sbt-ecr" % "0.16.0")build.sbtでECRにpushするための設定を行います。 本エントリではCloud9から同一リージョンのECRにコンテナイメージをpushする想定のため、regionの設定にはRegions.getCurrentRegionを使っています。
build.sbt
lazy val root = (project in file("."))
.enablePlugins(JavaAppPackaging, DockerPlugin, EcrPlugin)
.settings(dockerPackageSettings)
.settings(ecrSettings)
// 以降略
import com.amazonaws.regions.Regions
lazy val ecrSettings = Seq(
// Cloud9 と同じリージョンにある ECR に push する
region in Ecr := Regions.getCurrentRegion,
repositoryName in Ecr := "your-repository-name",
repositoryTags in Ecr ++= Seq(version.value),
localDockerImage in Ecr := (packageName in Docker).value + ":" + (version in Docker).value,
// Authenticate and publish a local Docker image before pushing to ECR
push in Ecr := ((push in Ecr) dependsOn (publishLocal in Docker, login in Ecr)).value,
)ECRにpushするための認証情報にアクセスできる環境で次のコマンドを実行すると、コンテナイメージのビルドとビルドしたイメージのECRへの登録ができます。
❯ sbt ecr:push3. Akka ManagementとAWS APIディスカバリーモジュールの導入
アプリケーションをECS上で起動するとタスクと呼ばれる単位に一意のPrivate IPが割り当てられます。 ここで割り当てられるIPを固定することはできません。 しかし、Akka Clusterの起動時にはシードノードを指定する必要があります。
Akka ManagementのAkka Cluster Bootstrapという機能を使うとシードノードをAkkaが自動解決してくれるようになります。
シードノードの自動解決を有効化するには、Akka Cluster Bootstrapが他のノードを見つけられるようにするためのディスカバリーモジュールを構成する必要があります。DNSを使うなど様々な方法が選択できるようになっていますが、ECS環境にデプロイするアプリケーションではAWS APIを使ったディスカバリーモジュールが利用できます。
build.sbt
val AkkaManagementVersion = "1.1.1"
libraryDependencies ++= Seq(
"com.lightbend.akka.management" %% "akka-management-cluster-bootstrap" % AkkaManagementVersion
"com.lightbend.akka.discovery" %% "akka-discovery-aws-api-async" % AkkaManagementVersion
)以降では、ECS環境でAkka Clusterを自動構成するための設定を示します。 ここに示したものにはアプリケーションを起動する環境ごとに差異の出やすい設定項目が多いです。 必要に応じてappliation.confに直接記述するのではなく、環境ごとの設定を分けて管理し、環境変数などを使ってapplication.confの設定を上書きするのがおすすめです。各設定項目のデフォルト値や詳しい説明はreference.confを参照してください。
application.conf
# reference.conf:
# https://github.com/akka/akka/blob/v2.6.14/akka-remote/src/main/resources/reference.conf
akka.remote {
# InetAddress.getLocalHost.getHostAddress でコンテナの Private IP を自動設定します
artery.canonical.hostname = "<getHostAddress>"
}
# reference.conf:
# https://github.com/akka/akka/blob/v2.6.14/akka-cluster/src/main/resources/reference.conf
akka.cluster {
# seed-nodes による自動構成は Akka Cluster Bootstrap よりも優先されてしまうため
# Akka Cluster Bootstrap を有効にするためには設定を空にしておく必要があります
seed-nodes = []
}
# reference.conf:
# https://github.com/akka/akka-management/blob/v1.1.1/cluster-bootstrap/src/main/resources/reference.conf
akka.management.cluster.bootstrap {
# デプロイ先の ECS サービスの名前を指定します
contact-point-discovery.service-name = "your-ecs-service-name"
}
# reference.conf:
# https://github.com/akka/akka-management/blob/v1.1.1/management/src/main/resources/reference.conf
akka.management.http {
# "" を設定した場合、InetAddress.getLocalHost.getHostAddress でコンテナの Private IP が自動設定されます
hostname = ""
# Akka Management の API コールを 9002 番ポートから受け付けるようにします
port = 9002
# "0.0.0.0" を指定し、全ネットワークインターフェースからリクエストを受け付けられるようにします
bind-hostname = "0.0.0.0"
# akka.management.http.port と同じ値を指定します
bind-port = 9002
}
}
# reference.conf:
# https://github.com/akka/akka-management/blob/v1.1.1/discovery-aws-api-async/src/main/resources/reference.conf
akka.discovery.aws-api-ecs-async {
# デプロイ先の ECS クラスターの名前を指定します
cluster = "your-ecs-cluster-name"
}補足: InetAddress.getLocalHost.getHostAddressについて
Akka Managementのドキュメントにはawsvpcモードで構成したECSではInetAddress.getLocalHost.getHostAddressが例外をスローするという注書きがあります。しかし、日本国内の東京リージョン及び大阪リージョンにおいてはECSコンテナが自分自身のホスト名からPrivate IPを解決できるためこの例外は発生しないようです。そのため、前述した設定ではInetAddress.getLocalHost.getHostAddressを使うよう設定した項目があります。
InetAddress.getLocalHost.getHostAddress throws an exception when running in awsvpc mode (because the container name cannot be resolved), so you will need to set this explicitly.
Lightbend Inc. AWS API • Akka Management,(参照 2021/09/16)
他のリージョンについては調査していないため、他のリージョンでは例外の発生する可能性が残っています。
Akka Managementに設定したポート9002をdockerExposedPortsに追加しておきます。
build.sbt
lazy val dockerPackageSettings = Seq(
mainClass in Compile := Some("com.example.Main"),
packageName in Docker := (name in ThisBuild).value,
dockerBaseImage := "adoptopenjdk:8-jdk-hotspot",
dockerExposedPorts := Seq(
9001, /* HTTP (service API) */
9002, /* HTTP (Akka Management API) */ // ← 追加
25520, /* TCP (Akka Cluster/Remote) */
),
)ECSでAkka Clusterを自動構成する際に、Akka Clusterをより安全に起動するために次の設定を追加しておくことを推奨します。 次の設定を有効にすることでスプリットブレイン状態になりアプリケーションの一貫性が崩れるリスクを回避できます。 スプリットブレイン状態については後続の「5. Split Brain Resolverの設定」のセクションで説明します。
環境変数AKKA_NEW_CLUSTER_ENABLEDをParameter Storeなどから設定できるようにしておき、 Akka Clusterの初回起動後、offに設定します。
application.conf
# reference.conf:
# https://github.com/akka/akka-management/blob/v1.1.1/cluster-bootstrap/src/main/resources/reference.conf
akka.management.cluster.bootstrap {
# Akka Cluster の新規形成を行うかどうかを指定します
# 環境変数 AKKA_NEW_CLUSTER_ENABLED から設定を変更できるようにしておき、
# 新規形成した後 off に設定変更できるようにします。
# 新規形成した後 off にすることでタスク再起動後などに既存クラスターへの参加ではなく
# クラスターの新規形成が行われ、スプリットブレイン状態に陥ってしまうリスクを回避できます。
new-cluster-enabled = on
new-cluster-enabled = ${?AKKA_NEW_CLUSTER_ENABLED}
}Akka Clusterのノードを一度全停止する場合はAKKA_NEW_CLUSTER_ENABLEDをonにしてから起動します。
4. ヘルスチェックAPIの有効化
アプリケーションの起動時にサーバーエラーを発生させないためには、ヘルスチェック専用のAPIを用意しておくことが重要です。 アプリケーションが処理を受け付ける準備が整っていない状態でロードバランサーがリクエストをルーティングしてくるのを防ぐためです。 HTTPのポートがLISTEN状態になったとしてもコネクションプールの立ち上げや、クラスターへの参加が完了していない可能性があります。 また、アプリケーションでOutOfMemoryErrorなどの致命的なエラーが発生した際にサーバーエラーを最小限に抑えるのにも役立ちます。
Akka ManagementにヘルスチェックAPIを提供する機能があるため、それを活用します。 Akka Cluster Bootstrapを有効にする際、すでにAkka Managementを導入済みのため追加で必要な作業はありません。
次のURLからアプリケーションが正常に稼働しているかどうかをチェックできます。 起動できている場合は200 OKでレスポンスが返ってきます。 アプリケーションが正常に稼働していない場合は500 Internal Server Errorがレスポンスされます。
http://<host>:<port>/alive
<host>: コンテナのPrivate IP<port>:akka.management.http.portに設定した番号
次のURLからアプリケーションにリクエストをルーティング可能かどうかをチェックできます。 ルーティング可能な場合は200 OKでレスポンスが返ってきます。 ルーティングを拒否するケースでは500 Internal Server Errorがレスポンスされます。
http://<host>:<port>/ready
ヘルスチェックAPIが2つある理由の詳細は次のページを参照してください。
Health checks • Akka Management
5. Split Brain Resolverの設定
ステートフルなアプリケーションをマルチAZで冗長化した場合、AZ間のネットワークに障害が発生するとAZ間で状態を同期できなくなり、いわゆる「スプリットブレイン」状態に陥ることを考慮すべきです。
ネットワークの障害で生存が確認できなくなったノードを単純にメンバーから除外すると危険です。 仮にメンバーを除外し、除外したメンバーが担っていた部分を回復させたとすると、分断した双方のクラスターでそれが行われ一貫性を維持できなくなるからです。
Akkaにはスプリットブレイン状態になったとしても一貫性を維持しながら機能を回復させるSplit Brain Resolverという機能があります。この機能はネットワーク障害により2つに分断されてしまったクラスターのどちらか片方をシャットダウンします。その後、シャットダウンしたメンバーをクラスターから除外することで除外したメンバーが担っていた部分を生き残った側が引き継ぐことで機能を回復させます。
Akka ClusterではデフォルトでSplit Brain Resolverが有効になっています。 デフォルトでは次のように元のクラスターメンバーの過半数の生存が確認できる側だけ生き残らせるkeep-majorityという戦略が有効になっています。 必要に応じて他の戦略を選択できます。
詳細は次のページを参照してください。
Split Brain Resolver • Akka Documentation
デフォルトの設定:
# reference.conf:
# https://github.com/akka/akka/blob/v2.6.14/akka-cluster/src/main/resources/reference.conf
akka.cluster {
downing-provider-class = "akka.cluster.sbr.SplitBrainResolverProvider"
split-brain-resolver {
active-strategy = keep-majority
}
}6. アプリケーションの起動・停止シーケンスの調整
サーバーエラーが発生する可能性をできるだけ少なくするためには、次のポイントを実現する必要があります。
- アプリケーションの起動時はリクエストが受け付けられる状態になってからロードバランサーからリクエストをルーティングしてもらう
- アプリケーションの停止時は段階的に停止処理を行い仕掛中の処理を中断しない
次の図で示した流れになるようアプリケーションの起動・終了シーケンスを調整します。
下に向かう起動処理は単純に前段の起動処理が完了した後に次の起動処理を行うよう実装します。 上に向かう停止処理の実装にはAkkaのCoordinated Shutdownという機能が使えます。

以降では、上記起動・終了シーケンスの各ステップでどのような実装を行えば良いのか解説します。
ActorSystemの作成など、実装が自明な部分については省略します。
◆ 起動処理:外部システムに接続
RDBなどアプリが利用する外部システムへの接続を行います。 外部システムが利用可能になっているかヘルスチェックを行い、利用できない場合はアプリケーションを再起動し、 外部システムとの接続の確立をリトライします。
◆ 起動処理:ClusterにJoin
外部システムとの接続が確立した後、次のコードを実行してAkka Clusterを起動します。
AkkaManagement(system).start()
ClusterBootstrap(system).start()Akka Clusterの起動が完了した直後から既に起動している他のノードからコマンドが送られてきます。 そのため、この操作を行う前にアプリケーションが正常に処理を行える状態にしておくことが重要です。
一方で、クラスターへの参加が完了するよりも前にロードバランサーからリクエストを受け取ってしまうと、 Akka Clusterの機能を使う処理が失敗してしまいます。 クラスターへの参加が完了する前にルーティング対象となるのを防ぐためAkka Clusterのヘルスチェックを有効にします。
次のモジュールを追加すると、クラスターに参加するまで/readyのヘルスチェックが200 OKになるのを防げます。
build.sbt
val AkkaManagementVersion = "1.1.1"
libraryDependencies ++= Seq(
"com.lightbend.akka.management" %% "akka-management-cluster-http" % AkkaManagementVersion
)このモジュールはAkka ManagementにAkka Clusterを管理するためのHTTP APIも追加します。 詳細は次のページを参照してください。
Cluster HTTP Management • Akka Management
◆ 起動処理:HTTPポートをbind
アプリケーションで定義したAkka HTTPのRouteをポートにbindします。
val interface = "0.0.0.0"
val port = 9001
Http().newServerAt(interface, port).bind(route)◆ 起動処理:ヘルスチェックでOKを返す
Akka HTTPのbindが完了した後に/readyのヘルスチェックを200 OKにします。
Akka HTTPの特定のポートの状態を確認する手段は調べた限り用意されてなさそうなので、独自にヘルスチェックを拡張します。
次のような単純なAkkaのExtenstionを作成します。 Extensionの詳細については次のページを参照してください。
Extending Akka • Akka Documentation
このExtensionは/readyのヘルスチェックで200 OKをレスポンスしてよいかどうかをAtomicBooleanで管理します。
package com.example
import akka.actor.typed.{ ActorSystem, Extension, ExtensionId }
import java.util.concurrent.atomic.AtomicBoolean
object AppCondition extends ExtensionId[AppCondition] {
override def createExtension(system: ActorSystem[_]): AppCondition = new AppCondition
}
class AppCondition extends Extension {
private[this] val ready = new AtomicBoolean(false)
def makeItReady(): Unit = {
ready.set(true)
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println("アプリケーションの準備が整いました")
}
def makeItUnhealthy(): Unit = {
ready.set(false)
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println("アプリケーションの状態を UNHEALTHY にします")
}
def isReady: Boolean = ready.get()
}実装したExtensionをAkka Managementのヘルスチェック機能に組み込みます。詳細については次のページを参照してください。
Health checks • Akka Management
AppConditionのisReadyを監視するクラスを実装します。
package com.example
import akka.actor.ActorSystem
import scala.concurrent.Future
class AppConditionHealthCheck(implicit system: ActorSystem) extends (() => Future[Boolean]) {
import akka.actor.typed.scaladsl.adapter._
private[this] val status = AppCondition(system.toTyped)
override def apply(): Future[Boolean] = {
Future.successful(status.isReady)
}
}次のように設定を追加してAkka Managementに直前で実装したクラスを登録します。
application.conf
# reference.conf:
# https://github.com/akka/akka-management/blob/v1.1.1/management/src/main/resources/reference.conf
akka.management {
health-checks {
readiness-checks {
AppConditionHealthCheck = "com.example.AppConditionHealthCheck"
}
}
}Akka HTTPのbindが返すFuture[ServerBinding]はポートのbindが完了したときに完了します。
次のようにforeachなどでAppCondition#makeItReady()を実行してヘルスチェックが成功するようにします。
import akka.http.scaladsl.Http
val appCondition = AppCondition(system)
val interface = "0.0.0.0"
val port = 9001
Http().newServerAt(interface, port).bind(route).foreach { _ =>
appCondition.makeItReady()
}次のセクションからはアプリの停止処理について説明します。
◆ 停止処理:ヘルスチェックでNGを返す
最初にロードバランサーのルーティング対象からコンテナを外す必要があります。 後続の停止処理で新しいHTTPリクエストが拒否されるようになるからです。
ここでは直前の「ヘルスチェックでOKを返す」で実装したAppConditionとAkkaのCoordinated Shutdownを組み合わせます。
次のような実装を行います。
import akka.Done
import akka.actor.CoordinatedShutdown
import scala.concurrent.duration._
import scala.concurrent.Future
val appCondition = AppCondition(system)
CoordinatedShutdown(system)
.addTask(CoordinatedShutdown.PhaseBeforeServiceUnbind, taskName = "make-app-condition-unhealthy") { () =>
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println("停止処理のため、状態を UNHEALTHY にします")
appCondition.makeItUnhealthy()
val finiteDuration = 15.seconds
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println(s"停止処理のため、状態を UNHEALTHY にしてからロードバランサーから切り離されるまで ${finiteDuration.toString} 待ちます")
akka.pattern.after(finiteDuration)(Future.successful(Done))
}この実装ではappCondition.makeItUnhealthy()をコールして/readyの状態をUNHEALTHYにした後、 ロードバランサーがそれを検知するまで15秒待っています。
補足:ECS側の操作でコンテナが停止するときのロードバランサーの振る舞い
ローリングアップデートなど、ECS側からコンテナを停止する際はロードバランサーのターゲットグループから除外された後に停止のためのSIGTERMシグナルがアプリケーションプロセスに通知されるようです。
サービスが Application Load Balancer (ALB) を使用している場合、ECS は SIGTERM シグナルを送信する前に、ロードバランサーのターゲットグループから自動的にタスクを登録解除します。タスクが登録解除されると、新しいリクエストはすべてロードバランサーのターゲットグループに登録されている他のタスクに転送されます。そのタスクへの既存の接続は、登録解除の遅延の期限が切れるまで (draining 中は) 続行できます。
Amazon Web Services, Inc. ECS のアプリケーションを正常にシャットダウンする方法 | Amazon Web Services ブログ,(参照 2021/09/16)
このドキュメントではApplication Load Balancer (ALB)の説明がされていますが、NLBでも同じ振る舞いである可能性が高いです。
そのため、停止処理の最初にヘルスチェックをUNHEALTHYしておく必要がないようにも思えますが、実際はこの動きが必要になる場合があります。 それはアプリケーション内でOutOfMemoryErrorなど致命的なエラーが発生した場合です。
Akkaではこのようなエラーが発生した場合でもCoordinated Shutdownを発動させます。 アプリケーション内で発生した事象が原因でアプリケーションの停止処理が開始するため、ロードバランサーが事前にターゲットグループからタスクを除外するという処理を行えません。 最初にヘルスチェックをUNHEALTHYにすることでロードバランサーからの切り離しを行い、新しいリクエストが来るのを止めつつ仕掛中の処理を完了させてから停止できます。
◆ 停止処理:HTTPポートをunbind
Akka HTTPのポートを安全にunbindさせるため、ここでもCoordinated Shutdownを使います。
Akka HTTPのbindした後に得られるServerBindingには次のようなAPIがあります。
ServerBinding#unbind(): 新規リクエストの受け付けを停止。処理中のリクエストは中断しないServerBinding#terminate(): 処理中のリクエストの完了を待つ
これらのAPIを次のようにCoordinated Shutdownで呼び出します。
import akka.http.scaladsl.Http
import akka.Done
import akka.actor.CoordinatedShutdown
import scala.concurrent.duration._
val appCondition = AppCondition(system)
val interface = "0.0.0.0"
val port = 9001
Http().newServerAt(interface, port).bind(route).foreach { serverBinding =>
appCondition.makeItReady()
// 以降を追加
CoordinatedShutdown(system).addTask(CoordinatedShutdown.PhaseServiceUnbind, s"http-unbind") { () =>
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println(s"終了処理のため、$serverBinding をunbindします")
serverBinding.unbind()
}
CoordinatedShutdown(system).addTask(CoordinatedShutdown.PhaseServiceRequestsDone, s"http-graceful-terminate") { () =>
val hardDeadline = 20.seconds
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println(s"終了処理のため、$serverBinding の graceful terminate を開始します(最大で $hardDeadline 待ちます)")
serverBinding.terminate(hardDeadline) map { _ =>
// FIXME: 適宜アプリケーションで利用する Logger に置き換えてください
println(s"終了処理のための $serverBinding の graceful terminate が終了しました")
Done
}
}
}◆ 停止処理のまとめ
Coordinated Shutdownのフェーズと、実装が必要なタスクの内容を次の表にまとめました。
| 処理順 | フェーズ | タスクの追加 | 実装するタスクの内容 |
|---|---|---|---|
| 1 | before-service-unbind |
可 | ヘルスチェックでNGを返し、ロードバランサーからの切り離しを待つ |
| 2 | service-unbind |
可 | ServerBinding#unbind()を実行 |
| 3 | service-requests-done |
可 | ServerBinding#terminate()を実行 |
| 4 | service-stop |
可 | |
| 5 | before-cluster-shutdown |
可 | |
| 6 | cluster-sharding-shutdown-region |
不可 | – |
| 7 | cluster-leave |
不可 | – |
| 8 | cluster-exiting |
不可 | – |
| 9 | cluster-exiting-done |
可 | |
| 10 | cluster-shutdown |
不可 | – |
| 11 | before-actor-system-terminate |
可 | 外部システムを切断。RDBのコネクションプールをcloseするなど |
| 12 | actor-system-terminate |
不可 | – |
外部システムを切断する部分の説明はしませんでしたが、他の停止処理と同様にCoordinated Shutdownに停止処理を登録します。
補足:クラスターにJoin/Leaveする際はサーバーエラーの発生するリスクがあります
Akka Cluster Shardingを利用する場合、Coordinated Shutdownを利用していたとしてもローリングアップデート中にサーバーエラーの発生する可能性があります。
クラスターのメンバーがJoin/Leaveする際に起きるShardの移動(HandOff)で、次の条件を満たすメッセージがAkka内部で捨てられるため、タイムアウトが起きます。 これがサーバーエラーの原因になります。 Join後のShard移動はリバランスによって発生します。
- ShardCoordinatorが移動対象となったShardの利用停止を指示してから、全てのShardRegionが利用停止を合意するまでの間に
- 移動対象となったShardが移動前に所属していたShardRegionに届いた
- 移動対象のShard宛のメッセージ
これはAkkaが特定のActorのペア間で送信されるメッセージの順序は維持するという保証をするための仕様です。 Shardが移動中のメッセージはShardRegionによって転送が保留されます。しかし、この条件に当てはまるメッセージは他のノードから転送されてきたメッセージである可能性があります。Shardの移動完了後にそのようなメッセージを転送してしまうと、移動したShard宛の新しいメッセージよりも後に再送された古いメッセージが届いてしまうことがあり、メッセージ順序を保証できないからです。 次のとおり明示的に実装されています。
// must drop requests that came in between the BeginHandOff and now, // because they might be forwarded from other regions and there // is a risk or message re-ordering otherwise if (shardBuffers.contains(shard)) { val dropped = shardBuffers .drop(shard, "Avoiding reordering of buffered messages at shard handoff", context.system.deadLetters)Lightbend Inc. akka/ShardRegion.scala at v2.6.14 · akka/akka(参照 2021/10/19)
このサーバーエラーを回避するためには、リトライを実装する必要があります。 ただし、リトライを実装するためには対象となる機能が次のいずれかの特性を持つ必要があります。
- リトライにより重複して実行されても問題ないこと
- 重複して実行されると問題がある場合は、アプリケーションの実装で冪等性を保証できること
重複して実行されると問題があり、かつ冪等性を保証するのが難しい場合はクラスターがJoin/Leaveする際にサーバーエラーが発生するリスクを受け入れる必要があります。
Akka Clusterのアプリケーション向けにECSを設定する
ECSでは次の項目を設定します。
- コンテナヘルスチェック
- コンテナ停止タイムアウト
- ECSサービスのデプロイタイプ(バージョンアップ方法)
1. コンテナヘルスチェック
コンテナのヘルスチェックにはAkka Managementの提供する/aliveのヘルスチェックAPIが利用できます。
次のように設定します。
CMD-SHELL,curl --fail http://127.0.0.1:9002/alive || exit 1マネジメントコンソールでの設定例:

2. コンテナ停止タイムアウト
ECSでFargate起動タイプを使った場合、終了処理がトリガーされてからアプリケーション側で終了処理を完了するまでの間デフォルトで30秒間の猶予が与えられます。もう少し具体的な言い方をすると、アプリケーションがSIGTERMシグナルを受け取ってからプロセスを停止するまで30秒間の猶予が与えられます。30秒を過ぎるとSIGKILLシグナルによりプロセスが強制終了させられます。
AkkaのCoordinated Shutdownでは終了処理に30秒よりも長い時間を要する可能性があります。Coordinated Shutdownの各フェーズにタイムアウト値がされているため、その合計よりも長い時間をECS側のタイムアウト値に設定したほうが良いです。 SIGKILLシグナルによりCoordinated Shutdownの処理が中断してしまうと仕掛中の処理が中断したり、Akka Clusterが不安定になりサーバーエラーの発生するリスクがあります。
Coordinated Shutdownの各フェーズのタイムアウトのデフォルト値は次のようになっています。合計で165秒のためECSにもそれと同じか、もしくは少し余裕を見て少し長いタイムアウト値を設定しましょう。
| フェーズ | デフォルトタイムアウト |
|---|---|
before-service-unbind |
15s |
service-unbind |
15s |
service-requests-done |
15s |
service-stop |
15s |
before-cluster-shutdown |
15s |
cluster-sharding-shutdown-region |
10s |
cluster-leave |
15s |
cluster-exiting |
10s |
cluster-exiting-done |
15s |
cluster-shutdown |
15s |
before-actor-system-terminate |
15s |
actor-system-terminate |
10s |
| 合計 | 165s |
引用元: Coordinated Shutdown • Akka Documentation
マネジメントコンソールでの設定例:

Coordinated Shutdownのフェーズごとのタイムアウト値をカスタマイズした場合はECS側のタイムアウトも調整の必要がないか確認しましょう。
3. ECSサービスのデプロイタイプ(バージョンアップ方法)
ECSサービスのデプロイタイプには「ローリング更新」を採用します。 一般的にはローリングアップデートと呼ばれる手法です。
ローリングアップデート以外の戦略としてはBlue/Greenデプロイがあります。しかし、本エントリで想定しているアプリケーションはステートフルであり、Blue/Greenデプロイの戦略をとってしまうとBlueとGreenの環境でステートの一貫性が保証できません。例えば、アプリケーションのステートとして口座残高を持っていたとすると、Blue側で行った入金がGreen側に反映されないということが起きます。
Blue側を完全に停止してからGreen側にリクエストをルーティングするという方法もありますが、この方法だとゼロダウンタイムアップデートは実現できません。
Akka Clusterのアプリケーション向けにNLBを設定する
NLBでは次の項目を設定します。
- ヘルスチェック
ヘルスチェック
Coordinated ShutdownでHTTPのポートをunbindする前にロードバランサーから切り離せるように/readyのヘルスチェックAPIを指定します。 コンテナヘルスチェックで設定した/aliveとは違うパスであることに注意してください。
本エントリで想定しているアプリケーションに向けては次のように設定します。
| 項目 | 設定値 |
|---|---|
| プロトコル | HTTP |
| パス | /ready |
| ポート | 9002 |
| 成功コード | 200 |
さいごに
ECS環境でAkka Clusterを用いたアプリケーションを稼働させるため私たちが検討した方式をご紹介しました。
次回のエントリでは本エントリで紹介した内容を適用したアプリケーションと環境でローリングアップデートができるか、障害が発生したときにどのように振る舞うのかを確認したいと思っています。
※ 記載されている会社名、製品名は、各社の登録商標または商標です。
※ Amazon Web Services、AWS、Amazon API Gateway、Amazon Elastic Compute Cloud、Amazon Elastic Container Registry、Amazon Elastic Container Service、AWS Cloud9、AWS Fargate、Network Load Balancer、Application Load Balancerは米国その他の諸国における、Amazon.com, Inc.またはその関連会社の商標です。
※ Akka、Akka Cluster、Akka Cluster Bootstrap、Akka Cluster Sharding、Akka HTTP、Akka Management、Split Brain ResolverはLightbend, Inc.の商標です。