

投稿日
コミット履歴からプロジェクトの生産性&品質を可視化する試み
もくじ
はじめに
ソフトウェア開発の現場では、プロジェクトの生産性や品質を客観的に評価し、継続的な改善につなげることが重要です。
一方で、生産性や品質を定量化し、継続的に測定・可視化・分析を行うには、無視できない量の事前準備や追加作業が発生します。
では、「GitリポジトリのURLを入力するだけで、リポジトリの生産性・品質を可視化できる仕組み」があったらどうでしょうか。
本記事では、Gitリポジトリのコミット履歴を活用した生産性・品質の可視化手法について、実際の測定事例を交えてご紹介します。
想定読者
プロジェクトの生産性・品質可視化に興味がある人
背景と目的
過去のプロジェクトでは、設計不足による密結合・低凝集なソースコードが生産性低下や手戻り、プロジェクト遅延の原因となりました。
再発防止策として、現プロジェクトでは疎結合なアーキテクチャを採用し、加えてコマンドによるアプリ・コンポーネントのひな型自動生成の仕組みを導入しました。これにより、ソースコードの規模が大きくなっても設計品質の維持が期待できます。
また、生産性の抜本的な向上策としてAIエージェント「Cline」による自律的なタスク実行の仕組みも導入しました。
しかし、施策の効果を客観的に評価するためには、プロジェクトの生産性・品質を定量的に可視化する仕組みが不可欠です。
このような経緯で、私は生産性や品質を可視化する基盤を構築することになりました。
既存アプローチの棚卸し
生産性・品質可視化基盤の構築にあたり、まず既存手法の調査を行いました。
ソフトウェア開発分析データ集2022 | IPA 独立行政法人 情報処理推進機構によれば、生産性の一般的な定量指標としては、人月あたりのコード行数やファンクションポイントを測定する手法があります。
エンタプライズ系事業/定量的品質管理 | アーカイブ | IPA 独立行政法人 情報処理推進機構では、品質指標としてコードレビューの指摘件数やテストカバレッジの測定、バグ件数やリリース後の障害発生率のモニタリングなどが挙げられています。
これらの手法は蓄積された過去データとの比較が可能ですが、多くはウォーターフォールを前提に設計されており、アジャイル開発には適用が難しい場合があります。
また、昨今の開発プロセスへのAI導入により生産性や品質に大きな差異が生じる可能性が高く、過去データがそのまま参考値にならない恐れがあります。
また、リポジトリ分析ツールを用いて、コミット履歴から生産性や品質を測定する方法も存在します。以下は代表的なOSSの分析ツールです。
- gilot (https://github.com/hirokidaichi/gilot)
- code-maat (https://github.com/adamtornhill/code-maat)
これらのCLIツールは、Gitのコミット履歴を入力するだけで各種指標を計算・出力してくれます。
これにより過去プロジェクトでも測定可能で、自動化も容易ですが、プロジェクト単体での分析においては参考値が不足しているといった課題もあります。
今回測定対象となる前プロジェクト・現プロジェクトはいずれもアジャイル開発で進められており、従来型の生産性・品質指標では十分な比較や評価ができません。さらに、AI導入前後で生産性や品質に大きな変化が生じる可能性があるため、過去の参考データがそのまま使えないという課題もありました。
そこで、より現場に即した定量的な評価を行うため、
- コミット履歴という客観的なデータを活用できること
- 過去プロジェクトにも遡って測定可能であること
- 自動化・継続的なデータ更新が容易であること
- アジャイル開発やAI支援導入後のプロジェクトにも適用できること
といった理由から、コミット履歴ベースの生産性・品質分析を採択しました。
コミット履歴ベースの生産性・品質測定
どのようにコミット履歴から指標を計算するのか
コミット履歴には、コミットID、日時、変更ファイル名、追加行数、削除行数、作者名など、開発活動の記録が含まれています。
これらの情報を加工・集計することで、開発チームや個人の生産性、設計品質、作業傾向など、さまざまな指標を定量的に算出することが可能です。
たとえば、追加・削除行数の集計からコードの変更量を把握したり、変更ファイルの組み合わせを分析したりすることで設計上の結合度や凝集度を評価できます。
このようにコミット履歴を適切に加工することで、可視化基盤のデータソースとして活用することができます。
可視化基盤の全体像
可視化基盤は、コミット履歴を加工・集計しグラフとして可視化するパイプラインを提供します。
Gitリポジトリからデータを取得し、スクリプトで指標を計算、データベースに格納。
Webダッシュボードで可視化し、初期設定後は自動でデータ更新できる仕組みをDockerコンテナ群として構築しています。
利用者は監視したいGitリポジトリのURLを入力するだけで、継続的にダッシュボードで生産性・品質指標を可視化できます。
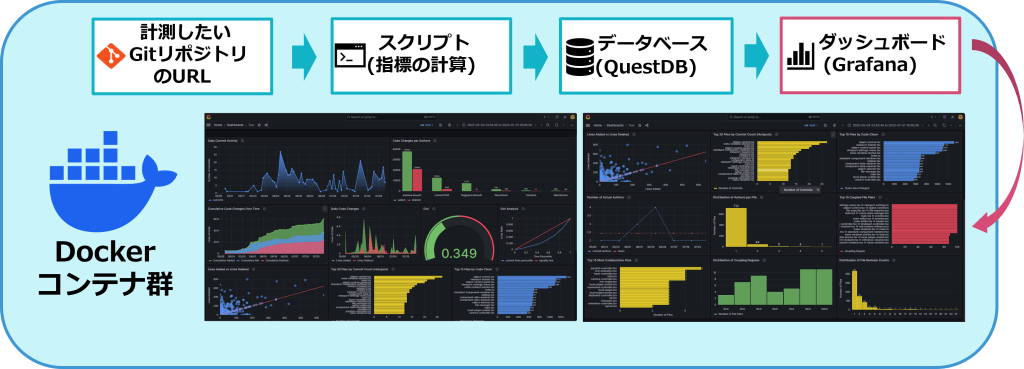
構成は以下の通りです。
・スクリプト: Python (Welcome to Python.org)
・データベース:QuestDB (QuestDB | Next-generation time-series database)
・ダッシュボード:Grafana (Grafana: オープンなオブザーバビリティ・プラットフォーム | Grafana Labs)
分析手法・指標
本記事では可視化基盤で採用した分析手法のうち、特に分かりやすく生産性・品質を可視化した以下2つをピックアップしてご紹介します。
チャーン分析(生産性の分析)
チャーン分析とは、ソフトウェア開発における「コードの変更量」に着目した分析手法です。
具体的には、コミット履歴から「いつ」「誰が」「どのファイルを」「何行追加・削除したか」といった情報を集計し、開発活動の活発さや効率を可視化します。
この分析により、
- 追加行数が多い=新規開発や機能追加が進んでいる
- 削除行数が多い=リファクタリングや手戻りが発生している
といった傾向を把握でき、日々の開発状況や生産性の変化を定量的に評価できます。
|
指標名 |
意味 |
計算式 |
|---|---|---|
| チーム生産性 [L/day] | チームがソースコードを1日に何行増やしたか | (総追加行数 – 総削除行数) / 開発日数 |
| 個人生産性 [L/p/day] | 1人の開発者がソースコードを1日に何行増やしたか | (総追加行数 – 総削除行数) / 開発日数 / 著者数 |
| 総削除行数割合 [%] | 開発期間内に削除した行数の追加した行数に対する比率
100%ならファイルは削除済 |
総削除行数 / 総追加行数 |
カップリング分析(品質の分析)
カップリング分析とは、ソースコードの「設計品質」に着目した分析手法です。
コミット履歴から「同時に変更されたファイルの組み合わせ(ファイルペア)」を抽出し、どのファイル同士が頻繁に一緒に変更されているかを分析します。
この分析により、
- 特定のファイルが頻繁に同時変更されている場合=設計上の密結合や低凝集の兆候
- 関連性の高いファイル同士のみが結合されている場合=疎結合・高凝集な設計が維持されている
といった設計品質の良し悪しを、客観的なデータから評価できます。
|
指標名 |
意味 |
計算式 |
|---|---|---|
| ペア別カップリング度 [%] | 同時にコミットされたファイルペアの頻度 | 同時コミット数 / コミット数が少ない方のファイルのコミット数 |
| ペア別平均コミット数 | 同時にコミットされたファイルペアの平均数 | (ファイルAのコミット数 + ファイルBのコミット数) / 2 |
| ペア別カップリングスコア | 同時コミットの頻度を、ファイルのコミット数で重みづけ | ペア別カップリング度 × ペア別平均コミット数 |
測定対象・前提条件
先ほどご紹介した生産性・品質指標を実際のリポジトリで測定しました。
以下は測定したリポジトリの概要と、測定の前提条件です。
|
概要・条件 |
リポジトリA |
リポジトリB |
|---|---|---|
| 開発期間 [日] | 251 | 112 |
| 総ファイル数 | 1,540 | 509 |
| 開発者数 | 23 | 4 |
| 総コミット数 | 502 | 462 |
| 対象ファイル |
.ts, .tsx(Storybook・自動生成ファイルを除外) |
|
今回分析した2つのリポジトリは、開発期間や規模、関わった人数などに大きな違いがあります。
- 開発期間はリポジトリAが251日と、リポジトリBの約2倍です。
- 総ファイル数もAが1,540件とBの約3倍で、より大規模なプロジェクトであることが分かります。
- 開発者数はAが23名、Bが4名と、Aの方が多人数で開発されています。
- 総コミット数は両者とも500件前後です。
- 対象ファイルは本質的なソースコードのみを測定します。どちらのリポジトリもTypeScript系(.ts, .tsx)ですが、Storybookや自動生成ファイルは除外しています。
結果・考察
チャーン分析による生産性測定
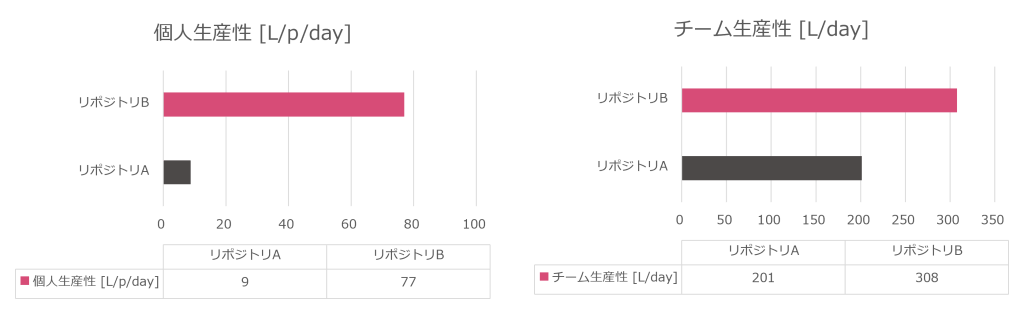
生産性の評価では、コミット履歴から「チーム生産性」と「個人生産性」を算出し、グラフで比較しています。
このグラフは、各プロジェクト(リポジトリA・B)における1日あたりのコード追加・削除行数をもとに、生産性の違いを可視化したものです。
結果:
リポジトリB(現プロジェクト)の方が「チーム」「個人」両方の生産性が高いことが分かります。
考察:
リポジトリBは少人数・短期間で集中的に開発されたプロジェクトですが、AIエージェントの導入等施策が功を奏し、効率的な開発が実現できていると考えられます。
一方、リポジトリAは規模・期間ともに大きいものの、設計品質の低下や手戻りが生産性の足かせとなった可能性があります。
この結果から、現プロジェクトで導入した施策が生産性向上に寄与していることが示唆されます。
カップリング分析による品質測定
品質評価の一環として、コミット履歴からファイル間のカップリング(同時変更の傾向)をヒートマップで可視化しました。このヒートマップは、どのファイルペアがどれだけ頻繁に同時コミットされているかを色の濃淡で示しています。
結果:
- リポジトリAは名前が似ているファイル同士と、特定ファイルへの結合傾向が強い
- リポジトリBは名前が似ているファイル同士の結合傾向が強い
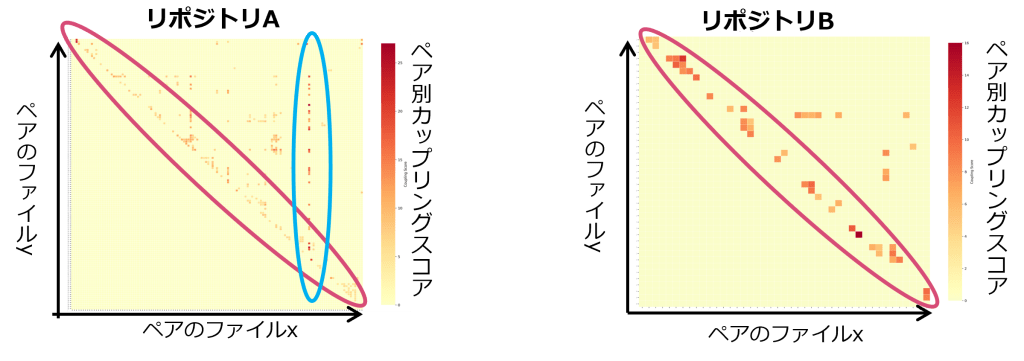
考察:
- 対角線上の分布(赤色で囲んだ部分)
ヒートマップの対角線上に分布が見られる場合、これは「似た名前のファイルペア」が同時にコミットされる傾向を示しています。例えばobject.ts(型定義ファイル)とobject.tsx(実装ファイル)のように、機能や役割が近いファイル同士が同時に変更されているケースです。これは、設計上適切なペアであることが多く、疎結合・高凝集な設計が維持されていることを示唆します。 - 垂直の分布(青色で囲んだ部分)
一方で、ヒートマップ上に垂直方向の分布が強く現れている場合、これは「特定のファイルの変更が責務をまたいで多くのファイルに影響している」ことを意味します。これは、特定ファイルへの依存度が高く、密結合な設計になっている可能性があり、設計上のリスクや改善ポイントを示しています。
以上を踏まえると、リポジトリBは名前が似ているファイル同士の結合傾向が強く、型定義ファイルと実装ファイルなど、設計上適切なペアに限られているため、疎結合・高凝集な設計が維持されていると評価できます。
一方、リポジトリAはBと同様に、似ているファイル同士の結合も多いですが、特定ファイルへの結合傾向も確認できます。このことから、部分的に密結合・低凝集な設計となっていることが分かります。これは、設計品質の低下や保守性の課題につながるリスクです。
まとめ・結論
本記事で紹介したコミット履歴ベースの生産性・品質分析は、従来の品質管理手法よりも手軽に、かつ継続的に可視化できる点が大きな特徴です。
今回の分析では、過去プロジェクト(リポジトリA)と現プロジェクト(リポジトリB)を比較し、
- チーム・個人の生産性が大幅に向上していること
- 設計品質も、密結合から疎結合・高凝集な構造へと改善されていること
が明らかになりました。
また、チャーン分析やカップリング分析といった手法を用いることで、単なる数値評価だけでなく、
「どのファイルがボトルネックになっているか」「設計上の問題がどこに潜んでいるか」といった、現場の改善に直結する具体的な示唆を得ることができました。
このように、コミット履歴を活用した定量的な分析は、開発プロセスの透明性を高め、チーム全体の意識改革や継続的な改善活動の推進にも寄与します。
今後の展望
今回得られた知見をさらに発展させることで、より高度な品質評価や改善サイクルの実現が期待できます。
具体的には、
- カップリング分析で可視化されたファイル同士の結合傾向を定量的に把握できる指標の開発
- 設計品質と生産性の相関関係を分析し、品質低下が実際に生産性低下に繋がるのかを検証
- さらに、AIを活用した自動分析レポートの生成や、問題箇所の自動特定・改善提案など、現場の意思決定を支援する機能の拡充
などを検討しています。
おわりに
ここまでお読みいただき、ありがとうございました。
コミット履歴を活用した分析は、軽量でありながら様々な示唆を得られることがお分かりいただけたでしょうか。
私自身、コミット履歴だけでも様々な情報を引き出せることに驚きました。
今回得られた知見を更に深掘りすることで、分析の実用性を高めていきたいと思います。